
In this project, I used Edge Impulse to implement an end-to-end prototype for motor condition monitoring using vibration analysis and machine learning, from raw data collection to live inference running directly on embedded hardware.
The primary goal was not to build a large or complex system, but to create an initial prototype that allows the condition monitoring workflow to be exercised, validated, and understood in a controlled and simplified setup.
This prototype was intended as a proof-of-concept to simulate the core diagnostic process used in industrial motor health monitoring, including mechanical coupling, signal integrity, baseline definition, anomaly detection, and iterative model refinement.
By validating this workflow on a minimal embedded platform, the system can later be scaled and adapted toward a more realistic industrial deployment in a subsequent project phase. This work focuses on validating the diagnostic pipeline rather than optimizing model accuracy.
Mechanical Setup and Signal Integrity
For this reason, I deliberately focused the initial phase of the project on mechanical stability and repeatability. The goal was to ensure that the vibration signal measured by the sensor genuinely originated from the motor’s operating behavior, not from unintended mechanical artifacts.
I designed and 3D-printed a custom mechanical fixture to rigidly couple the motor, propeller, and embedded processing board. Based on prior experience, I knew that poor mechanical coupling makes vibration analysis unreliable: the sensor ends up capturing structural looseness, fixture resonance, or assembly noise rather than the motor itself.


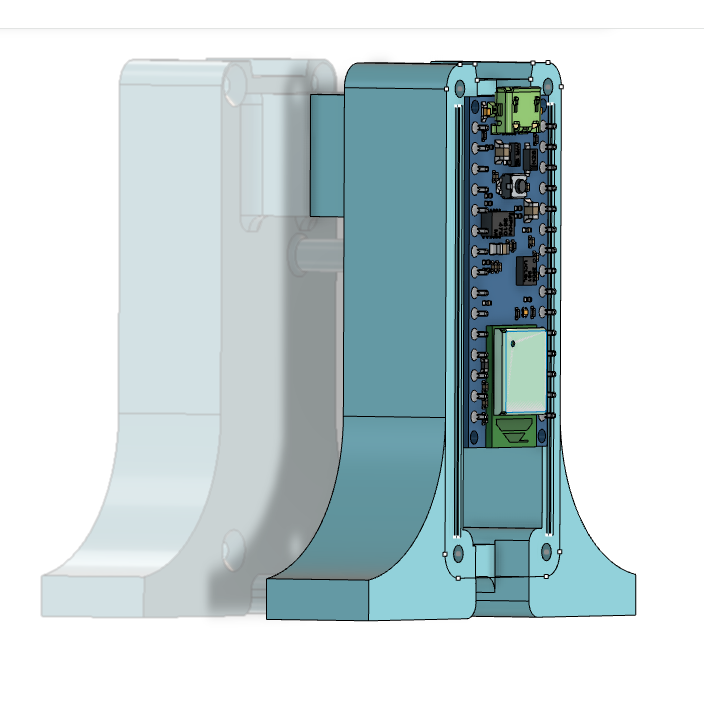
Embedded Platform and Data Acquisition
The processing platform used in this project is an Arduino Nano 33 BLE Sense, leveraging its built-in accelerometer as the primary sensor.
All data acquisition, signal processing, and inference are performed directly on the embedded device. During runtime, the system operates fully standalone, without reliance on an external computer or cloud-based processing.
This constraint was intentional, as it reflects real embedded deployments where latency, determinism, and limited computational resources are key design considerations.
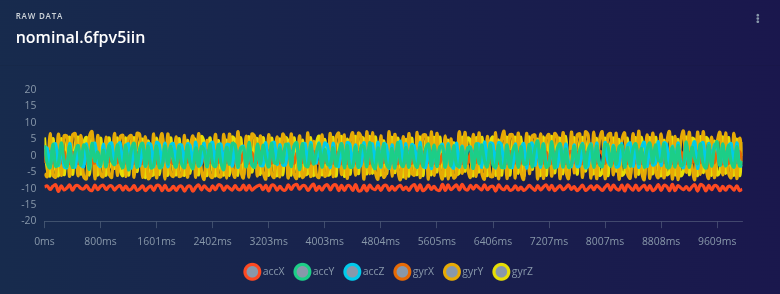
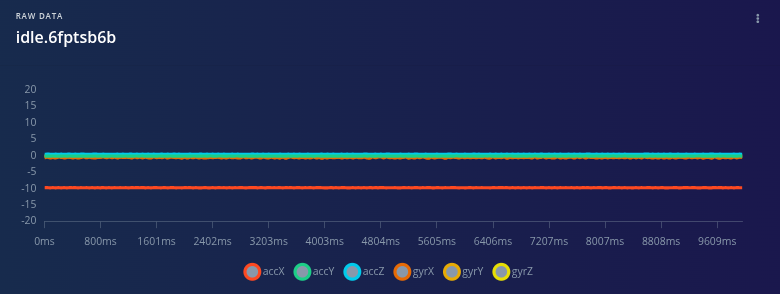
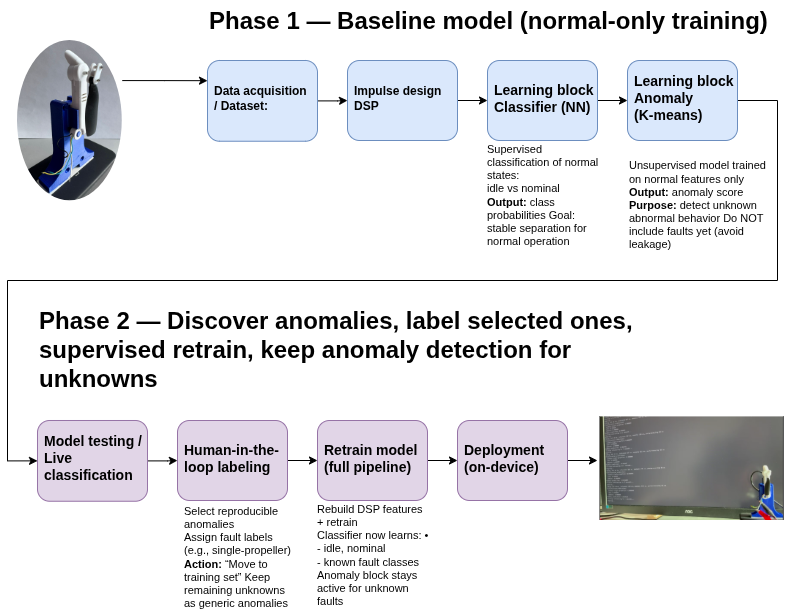
Phase 1 — Baseline Modeling with Unsupervised Anomaly Detection
In the first phase, I trained the system exclusively on healthy operating data. Two normal states were defined:
- Idle
- Nominal operation
At this stage, the objective was not to recognize specific faults, but to establish a reliable baseline representing normal system behavior.
An anomaly detection model was trained on this baseline, effectively learning what a healthy motor looks like in vibration feature space. Any deviation from this learned distribution is reported as anomalous.
This phase corresponds to an unsupervised learning approach: only normal data is provided, and the model learns the structure of normality rather than explicit fault classes.
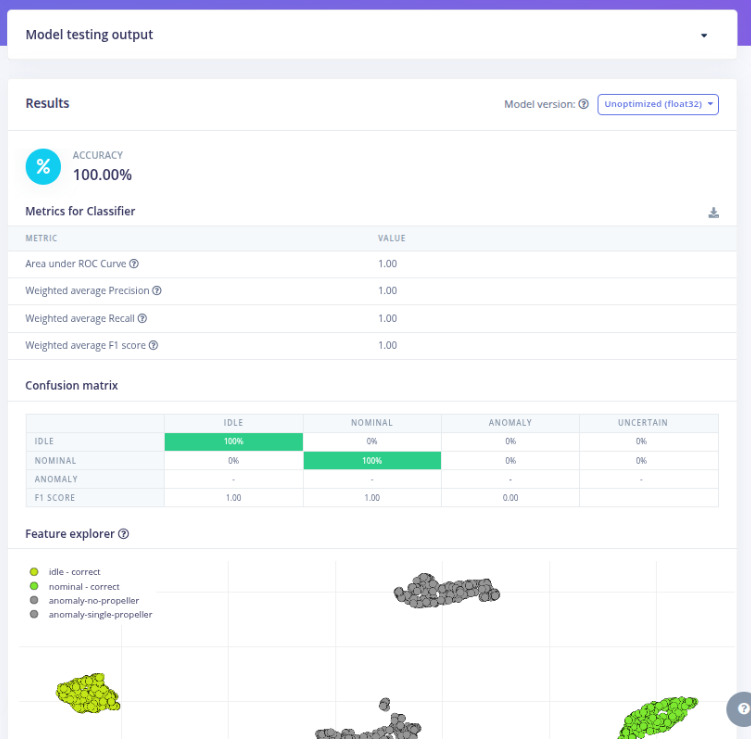
Phase 2 — Fault Injection and Anomaly Discovery
Once the baseline behavior was validated, deliberate mechanical faults were introduced. Examples include:
- Running the motor without a propeller
- Running the motor with a single, unbalanced propeller blade
These conditions produced vibration patterns that were clearly different from the baseline. When tested live on the embedded device, the system consistently detected these behaviors as anomalies. Fault coverage is intentionally limited to a small number of injected mechanical conditions.
At this point, the system demonstrated real-time anomaly detection directly on the device, using only embedded resources.
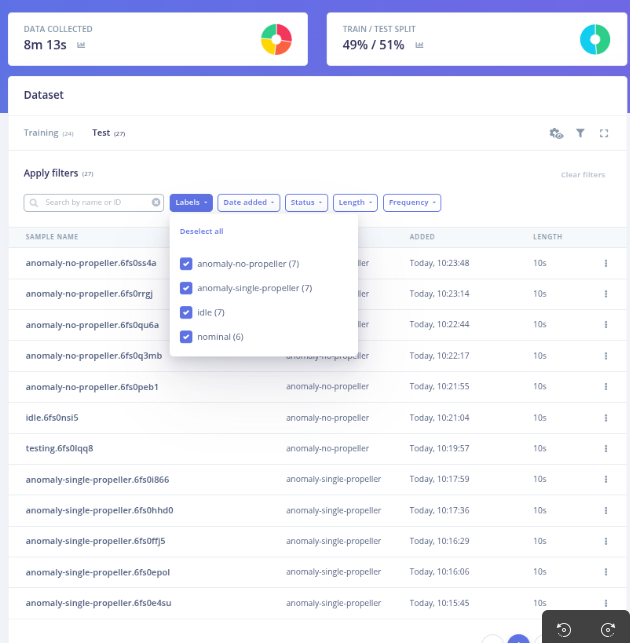
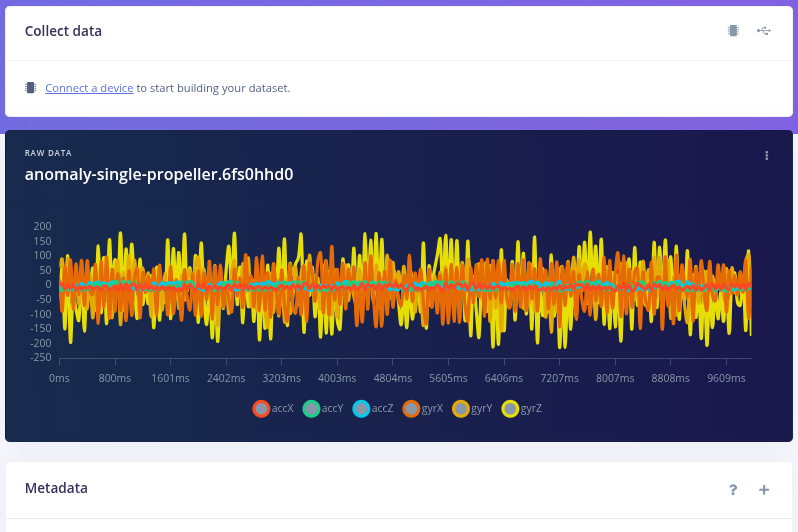
Phase 3 — Supervised Retraining with Known Faults
After observing consistent and reproducible anomaly patterns, selected anomalies were manually labeled and added to the training dataset.
This enabled a supervised retraining step, transforming the system from a pure anomaly detector into a hybrid model:
- Known behaviors (idle, nominal, specific fault types) are handled via supervised classification
- The anomaly detection block still captures unknown or previously unseen behaviors
In other words, the system explicitly recognizes certain fault modes while remaining sensitive to new, untrained anomalies.
This approach avoids closing the loop too early and preserves robustness as the system evolves.
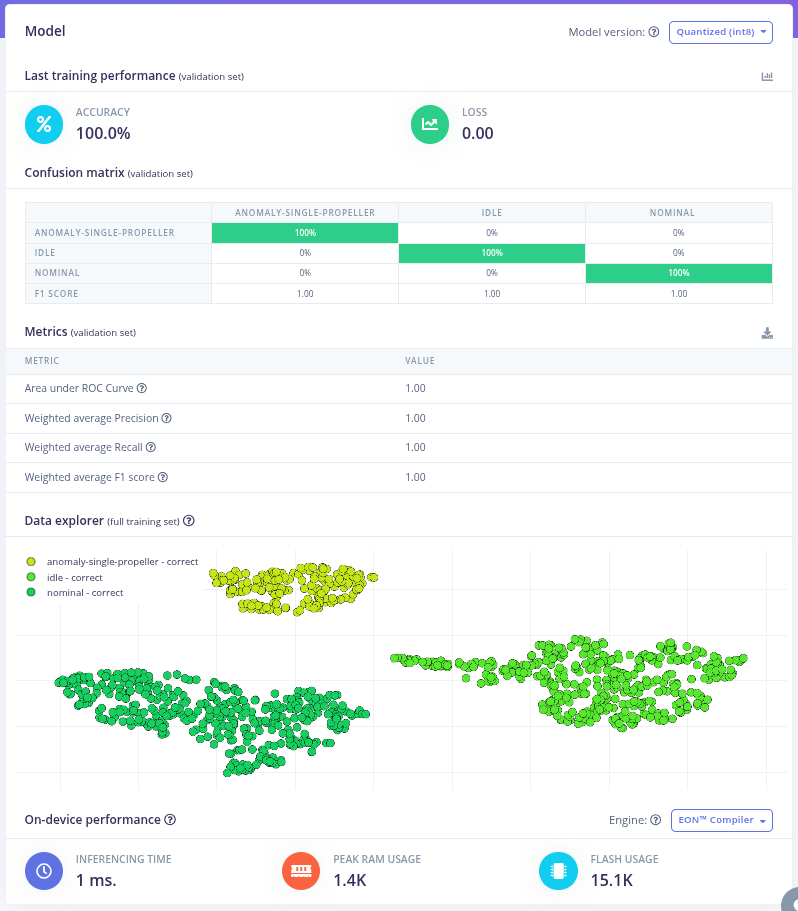
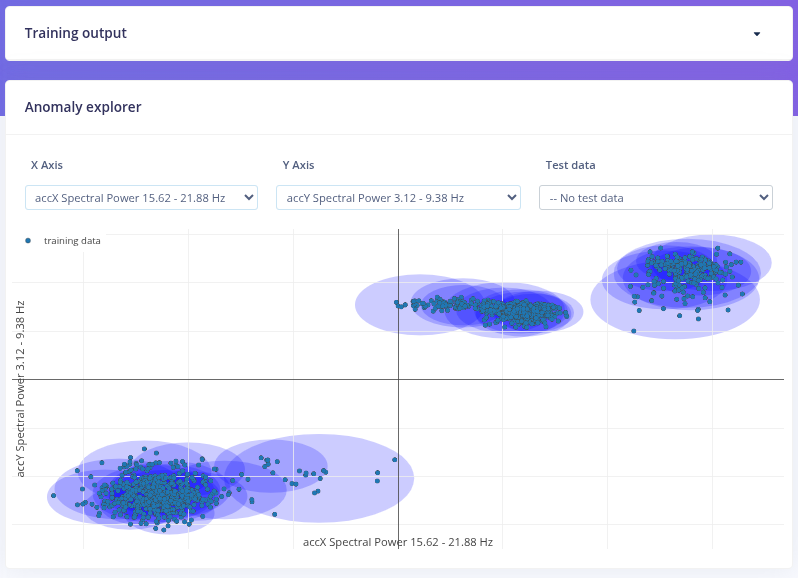
Deployment and Live Evaluation
After retraining, the updated model was deployed back onto the embedded device and evaluated during live operation.
Serial output logs show stable inference behavior, low latency, and interpretable class probabilities. Importantly, the anomaly detection mechanism remains active, ensuring that previously unseen faults are not silently misclassified as known states.
Engineering Perspective
The primary value of this project is not the machine learning model itself, but the complete engineering pipeline behind it:
- Mechanical design and vibration coupling
- Data acquisition under real physical constraints
- Baseline definition and anomaly strategy
- Decisions about when to keep anomalies generic and when to promote them to explicit classes
- Deployment and validation on embedded hardware
This is the same type of system-level thinking required in industrial condition monitoring applications, even though this prototype operates on a small motor and a compact development board.
Very interesting and useful, using low cost devices to condition monitoring is also my idea. I have a device with ESP32 with 4 accelerometers and 4 temperature sensors. If you want we can share experiences.
Thank you Jose for your comment. That sounds like a very solid setup. Using an ESP32 with multiple accelerometers and temperature sensors gives a lot of flexibility for condition monitoring, especially for vibration pattern comparison across different mounting points.
It would definitely be valuable to exchange experiences. I would be happy to discuss architecture choices, filtering strategies, and how you manage calibration and noise reduction.
If you are open to it, we can connect and continue the discussion in more detail.