A small note before we start.
I originally planned to wrap this whole series up in two posts. But I read something on the internet recently — scientists used AI to figure out what crows are saying to each other. And of course, sooner or later, AI is probably going to talk back to them. Remember the bird metaphor from Part 1? Maybe it wasn’t as much of a joke as I thought. https://www.nature.com/articles/d41586-025-00539-9
Anyway. Reading that, I felt a bit guilty. I was about to cut corners just to end the series at two posts. So I changed my mind. There will be a Part 3, and I want it to be a more practical one — closer to the hardware, less theory. We’ll get there.
For now, back to Part 2.
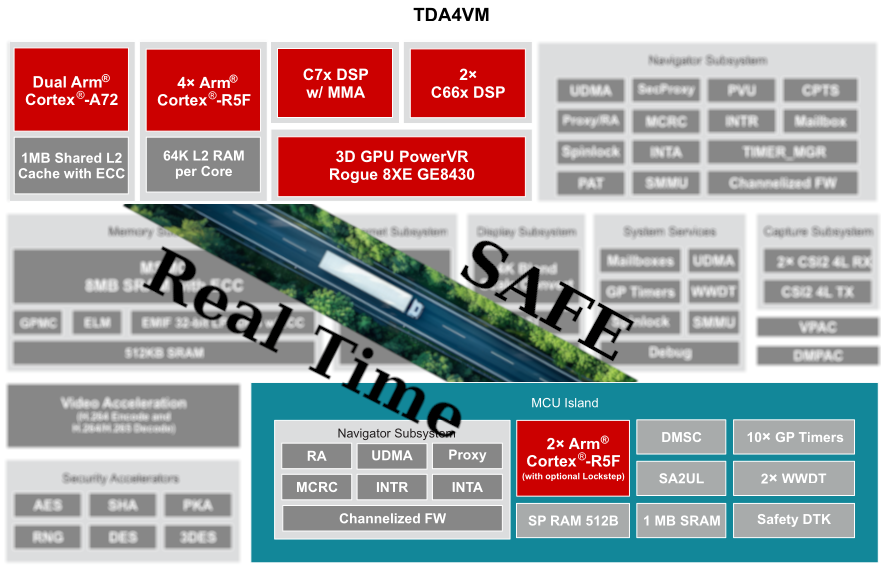
In Part 1 I covered what’s actually on the TDA4VM, where the famous 8 TOPS comes from in real silicon (a 64×64 INT8 MAC array on the MMA, running at 1 GHz), and the question I kept getting from readers — if it can’t learn, is it really AI? Short answer: yes, it’s inference silicon, like almost every edge AI chip, and that’s the category.
Part 2 is the harder half. This is where the marketing number meets reality.
In Part 2 I want to cover:
- Why precision completely changes the chip’s performance.
- The memory wall — why bandwidth, not compute, is usually what kills you.
- The TIDL software stack — what it actually does.
- And why a real YOLO model runs at about 2.24 TOPS effective, not 8.
Let’s go.
Precision changes everything
The first thing that surprised me when I dug into the MMA properly is how much the “8 TOPS” number depends on a single assumption: INT8.
INT8 means every weight and every activation in your network is stored as an 8-bit integer. That’s a small number. It can represent values from -128 to 127; that’s it. For a lot of vision models — image classification, object detection, segmentation — INT8 is enough. The accuracy loss compared to FP32 is usually less than 1%.
But not every model can live with INT8. Some models need more dynamic range. Radar processing. High-fidelity audio. Some sensitive parts of larger networks. For these, you need INT16 or even floating point.
Here’s what happens to the MMA’s performance when you change precision:
| Data type | MMA peak performance | Typical use |
|---|---|---|
| INT8 | 8 TOPS | Standard image classification, detection |
| INT16 | 2 TOPS | Radar, audio, high-dynamic-range |
| FP32 | 80 GFLOPS (C7x only — MMA not used) | Pre/post-processing, sensitive layers |
Two things to notice here.
First, INT16 gives you only a quarter of the throughput. That’s because each multiply takes more silicon at higher precision, so the MAC array effectively gives you fewer operations per cycle. Going from 8 TOPS to 2 TOPS just by changing precision is a big deal. If your model needs INT16, you’re not running on an 8 TOPS chip anymore — you’re running on a 2 TOPS chip.
Second, FP32 doesn’t use the MMA at all. The MMA is integer-only. If you push FP32 work through, it falls back to the C7x DSP’s vector units, which give you about 80 GFLOPS. That’s roughly 100 times less throughput than INT8 on the MMA.
This is why quantization is not optional on this hardware. If you bring a model trained in FP32 and try to run it as-is, you’re getting maybe 1% of the chip’s potential. You have to quantize it down to INT8 (or at worst INT16) to actually use the silicon.
The memory wall — where peak TOPS goes to die
There’s a number I want you to keep in your head as we go: 14.9 GB/s. That’s roughly the peak bandwidth of the TDA4VM’s external LPDDR4 memory interface (32-bit, typical configuration).
Now let’s compare that to what 8 TOPS actually demands.
If your model is 100 MB in size, just loading the weights from DDR into the accelerator at 14.9 GB/s would take about 6.7 ms. That’s before any input data, any activations between layers, anything. 6.7 ms for one forward pass of a model that small. At a 30 fps target, you have 33 ms per frame total — and you’ve already burned 20% of it on memory transfers, doing zero actual math.
This is what people call the memory wall, or the bandwidth wall. Modern accelerators are so fast at computing that the bottleneck is no longer “how many MACs per second” — it’s “how fast can you feed them data.”
To soften the wall, TI gave the TDA4VM 8 MB of on-chip L3 SRAM, called MSMC (Multicore Shared Memory Controller). This memory:
- Sits inside the SoC, close to the cores
- Is shared between A72, R5F, C7x, and the accelerators
- Has a much higher bandwidth than external DDR
- Has lower latency
- Is coherent across cores
The whole game of running a model efficiently on this chip is keeping the data inside that 8 MB window as much as possible. The TIDL toolchain (more on that next) tries to “tile” the model so weights and activations stay on-chip during compute, with DDR only used between layers.
When all the data lives in MSMC, you can hit close to peak TOPS. When you have to keep going out to DDR — because your model is too big, or your tiling is bad, or other cores are fighting for the bus — your effective TOPS drops fast.
This is also why “ideal conditions” matter. Peak TOPS is a compute-bound number. It only happens when the math units stay fed. The moment they have to wait for memory, you’re memory-bound, and the headline number on the box stops being relevant.
There’s a classic concept for this from HPC called the roofline model: every workload is limited by either compute or memory bandwidth, whichever runs out first. Vendors quote the compute ceiling. Real applications often hit the bandwidth ceiling long before they get there.
The software stack — TIDL
You don’t program the MMA directly. You use TIDL — TI Deep Learning.
TIDL is the bridge between the world you know (PyTorch, TensorFlow, ONNX) and the world the MMA needs (a specific instruction layout, a specific data layout, a specific operator set). You hand TIDL a trained model in a standard format, and it gives you back something the chip can run.

The most important piece of TIDL is the tidlModelImport tool. It does two big jobs:
- Quantization. It converts your FP32 model to INT8 (or INT16). To do this properly, it needs a small calibration dataset — a few hundred sample inputs that look like what the model will see in production. It uses these to figure out the right scale factors for each layer.
- Graph compilation. It looks at every layer of your model, decides what runs on the MMA, what runs on the C7x DSP, and what falls back to the A72 CPU. It also schedules data movement so the Streaming Engine can pre-fetch weights and activations into MSMC before they’re needed.
When TIDL does this well, your model flies. When it can’t — usually because your model has a layer it doesn’t support — that layer becomes a problem. The chip stops, the C7x or even the A72 has to handle it, and the pipeline stalls. We’ll see exactly what this costs in the next section.
Why 8 TOPS become 2 TOPS in real life
Here’s a number from the field that I think every honest blog post about this chip should mention:
A YOLO v3 model running on the TDA4VM achieves about 2.24 TOPS effective throughput — roughly 28% of the peak.
That’s not unique to the TDA4VM. Almost every accelerator in this class gets 20–40% of its peak number on real models. But it’s worth understanding why, so you don’t get surprised.
There are three main reasons the 8 TOPS turns into 2-something:
1. Unsupported operators. TIDL supports a wide range of operators (Conv, Pool, ReLU, BatchNorm, and common activations). But modern model architectures often invent new layers — custom activations, exotic attention blocks, weird normalizations. If your model has an operator that TIDL doesn’t natively support, that layer falls back to the C7x or the A72. The MMA sits idle while the slower core catches up. This is the biggest single cause of low efficiency.
2. Layer reformatting. The MMA wants data in a specific layout. If the previous layer produced data in a different layout (say, NHWC vs NCHW, or a different tile size), the C7x has to use part of its time shuffling data into the right shape. That work eats clock cycles but produces no MACs. It doesn’t show up in the TOPS number, but it shows up in your latency.
3. Kernel launch overhead. Small layers have a problem: the time to set up the Streaming Engine and kick off the MMA is a fixed cost. If the layer itself is tiny, you spend more time setting up than computing. Small operations don’t have enough math to “hide” the setup latency.
Put these three together and you get a model that, in theory, should run at 8 TOPS but in practice runs at 2.
The takeaway from this is something I want to be clear about:
8 TOPS is potential energy. The number that actually runs your model is kinetic energy. They’re not the same.
The TIDL graph compiler will tell you, after import, the effective GMACs your model uses. That number — calculated from the actual model graph — is much closer to what you’ll see in real life than the headline “8 TOPS”.
The camera pipeline — a quick teaser
There’s one more piece I haven’t covered yet, because it deserves its own post: how pixels actually get from the camera into the model. On this chip, that path goes through a hardware ISP, and if you get it wrong, you can lose all the advantage of the 8 TOPS accelerator in CPU pre-processing. It’s the kind of gotcha that catches people moving from a Raspberry Pi to the AI-64. That’s Part 3 of this series.
The honest takeaway
After all of this, here’s where I land on the BeagleBone AI-64:
- The 8 TOPS is real, but specialized. It’s INT8 only, MMA only, peak only. In a real application, expect 20–40% of that.
- Memory bandwidth is the real bottleneck. The 8 MB on-chip MSMC SRAM is more important than the 8 TOPS. Models that fit in MSMC fly. Models that don’t struggle.
- You have to use the software stack. TIDL is not optional. Quantization is not optional. If you try to skip these and “just run the model”, you’re throwing away the whole point of the chip.
- The chip is built for vision, not for transformers. Object detection, classification, segmentation — yes. LLMs, diffusion models, dynamic shapes — no. There is a Jetson for that.
It is not a small Jetson. It is not a Raspberry Pi with extra silicon. It’s an automotive-grade vision SoC that happens to be in a hobbyist board. Treat it like that, and it’s one of the most interesting boards you can buy at this price. Treat it like a generic AI dev board, and you’ll be frustrated.
Next time
In Part 3, I’ll dig into the camera pipeline — the VPAC, the ISP, and why you can’t pre-process frames on the A72 CPU and expect anything to work. After that, we’ll move on to actually running a model: take a quantized YOLO through the TIDL import flow, push it onto the AI-64, and measure FPS and latency for real. That’s where everything in these two posts stops being theory and turns into milliseconds you can plot.
Thanks to everyone who pushed back on the first version of this material. Half the value of blogging is people telling you when something needs more explanation.
That’s enough for tonight. Next time, we follow the pixels.
References
- Texas Instruments, TDA4VM Processors Datasheet (Rev. K).
- Texas Instruments, TI C7000 C/C++ Optimization Guide and Streaming Engine documentation.
- Texas Instruments, TI Deep Learning (TIDL) Product User Guide.
- Texas Instruments E2E Forums, Yolov7 MMA Achievable TOP efficiency on TDA platform.
- Texas Instruments E2E Forums, Peak DDR Bandwidth Calculation and DDR Performance Counter.
- BeagleBoard, BeagleBone AI-64 Overview — https://www.beagleboard.org/boards/beaglebone-ai-64
- Embedded Low-power Deep Learning with TIDL — Edge AI and Vision Alliance.